序言
- 编译器,教程: http://mooc.study.163.com/learn/1000002001?tid=1000003000#/learn/content?type=detail&id=1000023001&cid=1000019000
- 配套网站: http://staff.ustc.edu.cn/~bjhua/courses/compiler/2014/
正文
一. 编译器介绍
- 概念: 编译器是一个程序,核心功能是把源程序代码翻译成为目标代码
- 编译器核心功能如下图: 其中静态计算表示的是经过编译器后, 目标程序和源程序的功能需要相同
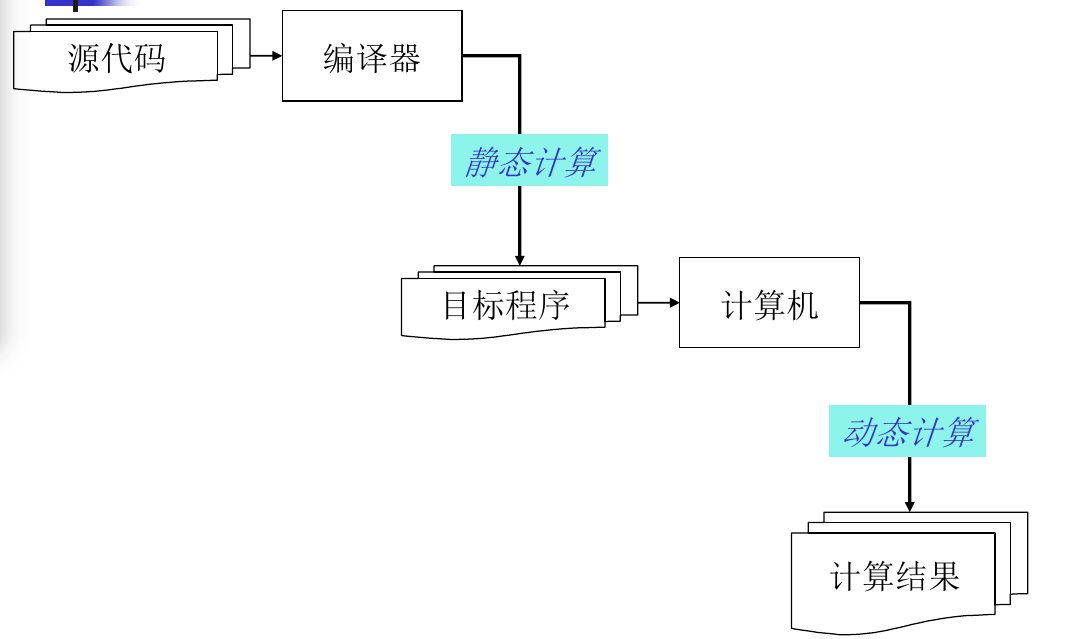
- 解释器: 也是处理程序的一种程序;(解释器是在线的方式,也就是说解释器解释程序之后实际上还会执行该程序,而编译器只是生成可执行文件,称为离线形式, 编译器输出为可执行程序, 而解释器输出为程序执行结果)
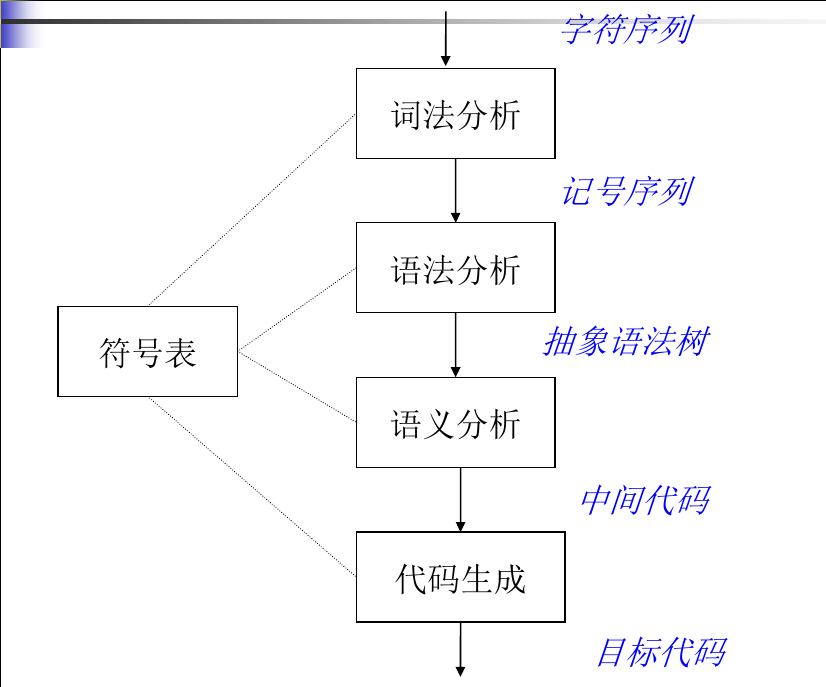
- 结构: 前端–>代码优化–>后端; 词法分析–>语法分析–>语义分析–>代码生成; (流水线模式)
- 编译器结构: 如下图(一个没有优化的编译器结构)
二. 词法分析
- 编译器可以分为一个前端和后端, 前端又可细分为如下:
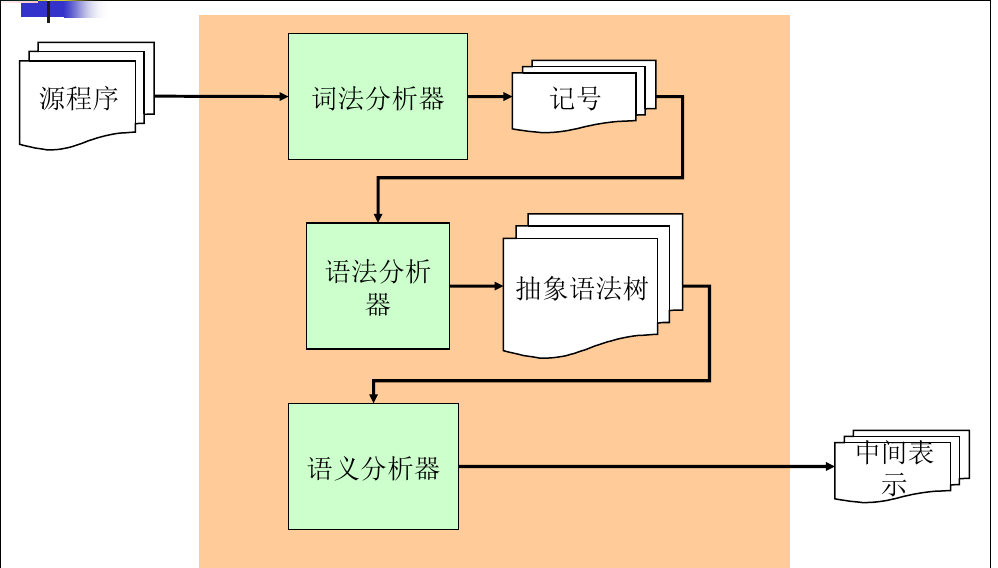
- 作用: 字符流–>词法分析–>记号流; (字符,关键字的切分等)
- 记号流: 编译器内部定义的数据结构, 编码所识别出的词法单元; 如下是一个
C语言实现的记号流的数据结构

- 词法分析的实现方法:
- 手工编码实现方法: 是目前非常流行的实现方法,如:GCC,LLVM
- 词法分析器的自动生成器: 可以快速成型,但是难以控制细节
- 手工分析法: 转移图(实际上有点类似状态转移,需要注意的是有的地方需要回滚(回滚的实现: 一个可以通过文件指针的回退,另一个是可以将文件内容读取到一个字符数组中,然后需要回退时将索引减一即可))
- 关键字表算法: 对给定语言的所有关键字构造一个Hash表,也就是对所有的标识符和关键字,先统一按标识符的转移图进行识别,识别完成后,再进一步查表看是否是关键字(关键字的完美Hash表: 完美哈希函数是没有冲突的的哈希函数,也就是,函数 H 将 N 个 KEY 值映射到 M 个整数上,这里 M>=N ,而且,对于任意的 KEY1 ,KEY2 ,H( KEY1 ) != H( KEY2 ) ,并且,如果 M = = N ,则 H 是最小完美哈希函数(Minimal Perfect Hash Function,简称MPHF)参考博文)
- 自动生成法(生成器): 通过一些转换工具,如: lex,flex,jlex等将正则表达式转换为词法分析器; 需要用到:
- 正则
- 有限状态自动机: 输入的串是否能被状态机接受(DFA(确定的),NFA(不确定的))
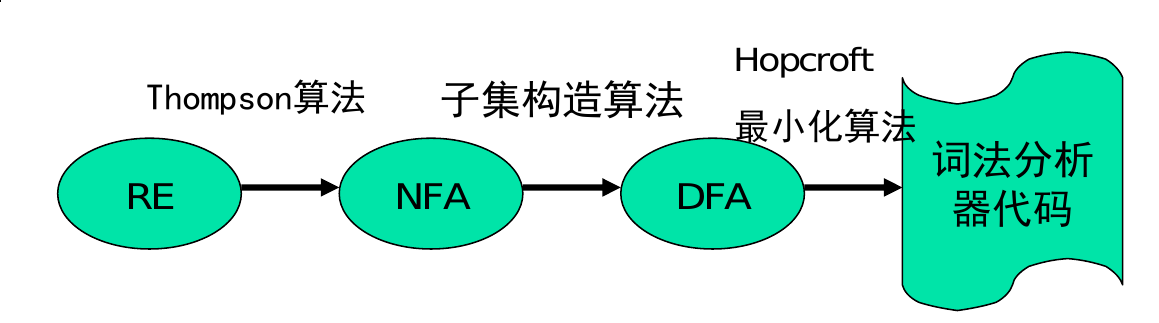
- 正则表达式到
NFA是Thompson算法,从NFA到DFA是子集构造算法,从DFA到词法分析器是Hopcraft最小化算法
- DFA: 确定状态有限自动机(只有一个状态)(词法分析器是一个DFA); NFA: 非确定有限状态自动机(有多个状态)
- 正则表达式转换为词法分析器:
三. 语法分析
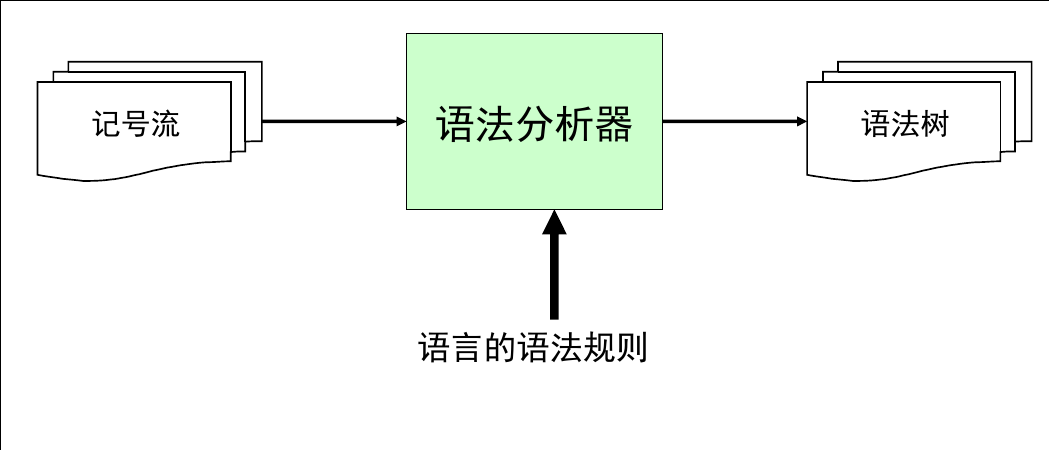
- 语法分析的数据工具: 上下文无关文法(乔姆斯基文法体系: 为研究自然语言提供的一系列数学工具)
