一、字符/Character
对用户可见的“一个字符”,通常是我们在屏幕上看到的一个字母、数字、emoji 或组合字符。
比如:a、é、👨👩👧👦
二、字符编码标准/字符集
字符编码标准定义的是如何将字符映射到唯一编码,常见的字符编码标准比如ASCII、Unicode、GBK等
2.1 ASCII
ASCII(7位)定义了 128 个字符的唯一编码,包括数字0到9、小写字母a到z、大写字母A到Z以及常用标点符号等。
2.2 Unicode
Unicode又叫万国码,目标是为所有字符定义唯一编码(Code Point)。为了解决ASCII/GBK不能定义全部字符的问题。
比如:
a -> U+0061
👨 -> U+1F468
注意:
Unicode只负责分配码位(Code Point),并不决定具体的存储形式。
Unicode的前 128 个码点与ASCII相同。
2.2.1 Code Point
Code Point也叫码位,Unicode中为每个字符分配的唯一编码。
一个字符可以对应一个或多个Code Point,比如:
a:U+0061,对应 1 个Code Point👨👩👧👦:U+1F468 (👨) + U+200D (ZWJ) + U+1F469 (👩) + U+200D (ZWJ) + U+1F467 (👧) + U+200D (ZWJ) + U+1F466 (👦)对应 7 个Code Pointé:U+00E9或U+0065 + U+0301
备注:
在Unicode中,
é实际上有两种表示方式:单一字符表示法:即直接使用
U+00E9这个单独的Unicode码位表示é。组合字符表示法:使用
U+0065(字母e)和U+0301(重音符号)两个Unicode码位来表示一个é字符。为什么会有这两种表示法?
历史原因:Unicode设计时考虑到了不同语言的需求,许多语言(如法语、西班牙语等)使用带有重音符号的字符,因此,Unicode同时支持这两种表示方式。
兼容性:一些旧的系统或字体可能只支持分解字符表示法,因此,Unicode也保留了这种组合字符的方式,以提高兼容性。
2.2.2 Code Unit
Code Unit也叫码元(代码单元),表示计算机中实际存储Unicode的基本单位,取决于编码方式。
比如:
-
UTF-8:Code Unit是 1 字节(8 Bit);比如:a在UTF-8编码下占 1 个字节,表示为0x61。 -
UTF-16:Code Unit是 2 字节(16 Bit);比如:a在UTF-16编码下占 2 个字节,表示为0x0061。 -
UTF-32:Code Unit是 4 字节(32 Bit);比如:a在UTF-32编码下占 4 个字节,表示为0x00000061。
三、字符编码方式
字符编码方式决定了字符如何存储、传输和解码;常见的编码方式有:UTF-8、UTF-16、UTF-32等
-
UTF-8:可变长度,用 1 到 4 个字节来存储 Unicode 字符;为了节省存储资源。 -
UTF-16:可变长度,用 2 或 4 个字节存储字符。 -
UTF-32:固定长度,每个字符始终使用 4 字节存储。
比如:
é的Code Point是:U+0065 + U+0301
当以UTF-32方式编码时,每个Code Point未超过4字节,所以表示为:0x00000065,0x00000301
当以UTF-16方式编码时,每个Code Point未超过2字节,所以表示为:0x0065,0x0301
当以UTF-8方式编码时,0x0301值超过了128,需要按UTF-8格式拆分为0xCC,0x81,所以表示为:0x65,0xCC,0x81
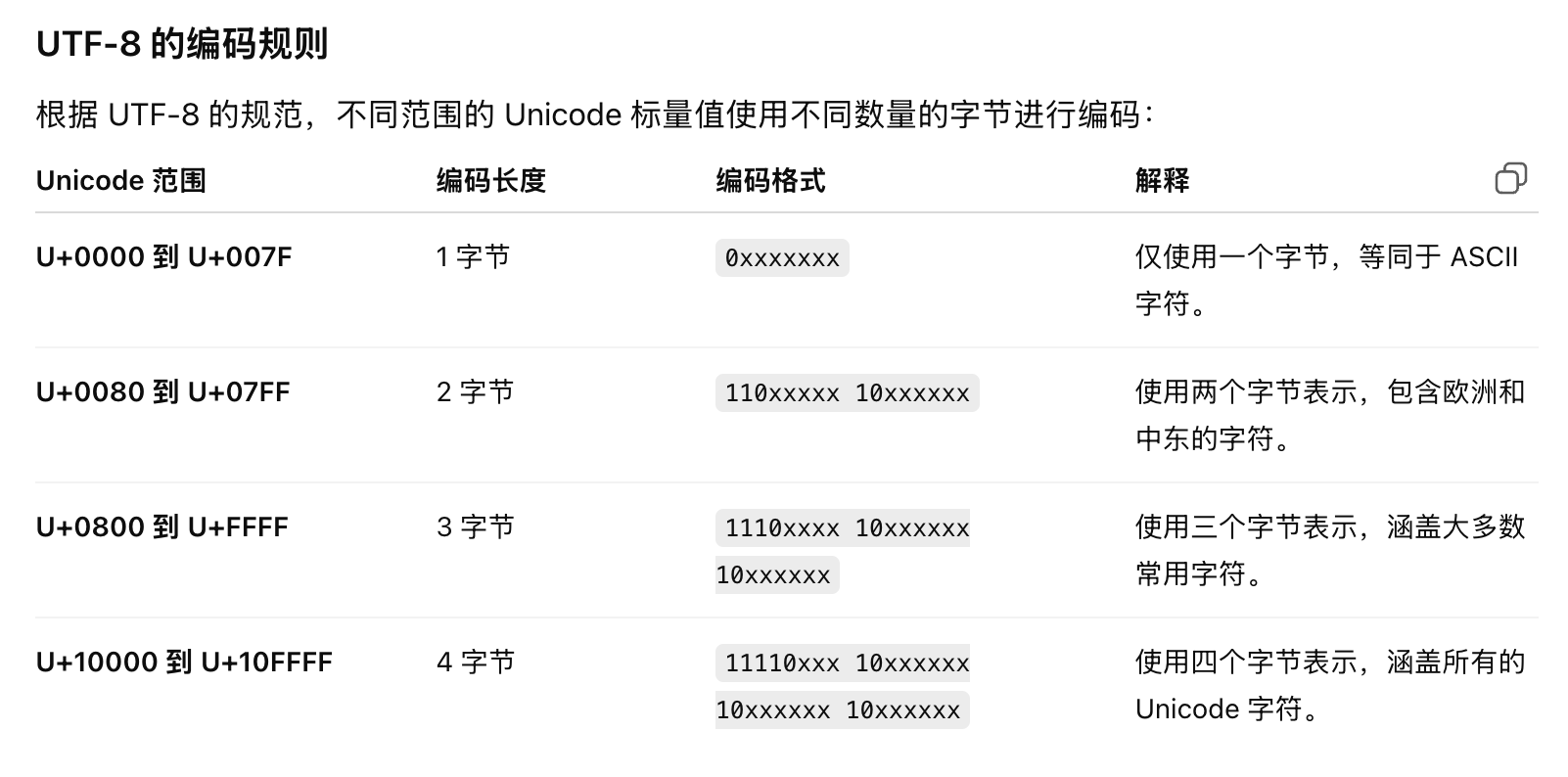
Q:
UTF-8编码为什么是按128做比较,按理说1字节(0xFF)表示的最大值是255?A:有两个原因:一是为了与
ASCII兼容,ASCII只支持了128个字符编码,在UTF-8编码中,前128位与ASCII编码相同;二是UTF-8编码中,会将第一个字节的高位部分用来标识这个字符的编码长度,具体为:
0xxxxxxx:表示 1 字节字符(ASCII范围)
110xxxxx:表示 2 字节字符
1110xxxx:表示 3 字节字符
11110xxx:表示 4 字节字符